
У веб-мастеров часто возникает ситуация, когда надо проанализировать чужой сайт или просто спарсить с него часть контента. Это может пригодиться для того, чтобы на основе полученного чужого контента делать дорвеи, отдавать текст на рерайт другим авторам или просто проводить первичный автоматический перевод с Google Translate.
Да и вообще: автоматический парсинг сайта или сайтов полезен в куче прикладных вещей, слабо связанных непосредственно с последующей контент-маркетингом. Например, достаточно часто техника применяется для парсинга страниц интернет-магазина, когда его лень наполнять самостоятельно; часто техника применяется для парсинга цен и уведомлении о наиболее приятной цены. Нередко парсинг сайтов (web dcraping) применяется просто для мониторинга новостей по определенной метке или тегу.
Впервые я столкнулся с Web Scraping как таковым достаточно давно, еще когда работал в web-студии. Тогда я пользовался Scrapinghub, однако, инструмент нельзя было назвать гибким. С появлением некоторого свободного времени и увлечении Python решено было сделать собственный инструмент. Однако, как показала праткика, сделать универсальный инструмент на все случаи жизни не получается: слишком разные сайты необходимо парсить, и к каждому нужен индивидуальный подход. В результате появился некоторый опыт, с которым и хотелось бы поделиться. Python-програмимсты Middle уровня и выше вряд ли найдут в этой статье что-то полезное, но новичкам, думаю, статья будет в масть.
Инструменты
Инспектор объектов Chrome
Как уже было сказано, уникальный скрипт создать весьма сложно. Данные хранятся в разных дивах разного уровня вложенности, и везде есть своя специфика. В 99% случаев перед непосредственно парсингом приходится вдумчиво изучать HTML-структуру исследуемых страниц, править код, и только потом натравливать скрипт на домен.
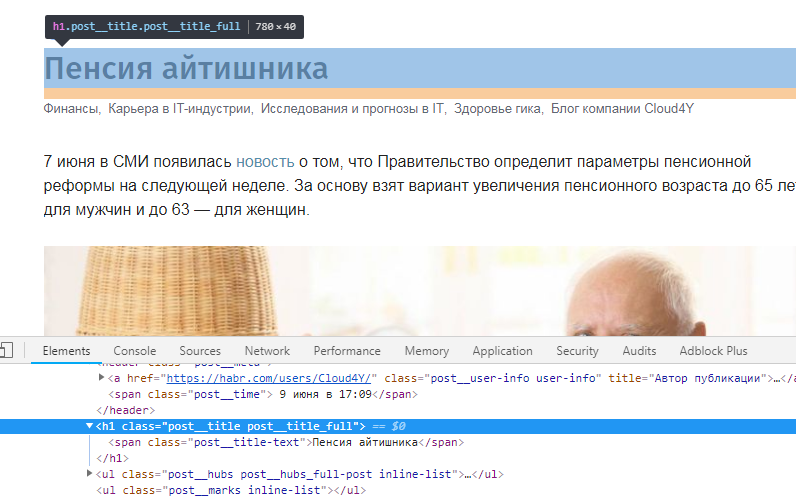
В подавляющем большинстве случаев для этого хватает встроенного в Chrome инспектора объектов. Например, хабр на странице поста хранит название статьи в строке post__title-text блока post__title post__title_full.
Scrapy
Есть готовый фреймворк для парсинга – Scrapy. Он удобен тем, что позволяет работать с куками (а, следовательно, обходит примитивные бот-детекторы), работать с задержкой, адекватно обрабатывает исключения. Однако вход к Scrapy достаточно высок, и лично я бросил этот фреймворк на полпути: мои прикладные задачи позволяют обходиться артиллерией меньшего калибра.
К тому же, для вебмастера, который пытается взять в займы чужой контент для своих доров, функционал Scrapy может показаться избыточным.
BeautifulSoup
BeautifulSoup – правая рука моего рукожопия. Она позволяет достаточно легко обрабатывать HTML, полученный с помощью библиотеки requests. Своего рода, золотая середина между собственный велосипедом и Scrapy, середина, которой лично я и пользуюсь.
Работает с BeautifulSoup, вам нужно быть готовым ктому, что вам придется самостоятельно обрабатывать исключения, в том числе связанные с блокировкой IP, самостоятельно думать об анонимизации и проксях, самостоятельно же городить способ экспортирования данных.
Основной функционал
Основной функционал заключается в том, чтобы просто забрать текст из нужного нам блока. Для этого стоит разобраться, в каких div-ах блок находится. Допустим, у нас есть следующая структура документа:
<div class=“page”>
<div class=“entrytext'”>
Нужный контент, который мы и сохраним.
</div>
</div>
Соответственно, чтобы достать «Нужный контент, который мы и сохраним», требуется сделать такое:
from bs4 import BeautifulSoup
s=requests.get(“http://primer-domena.ru/primer-stranisy.hrml”)
b=bs4.BeautifulSoup(s.text, "html.parser")
array=b.select('.page .entrytext')
result= array.getText()
Соответственно, если блоков, удовлетворяющих условию селектора несколько, то нужно выбрать нужный индекс в массиве p3. Ну а потом уже решать, что вам нужно, а что нет.
Возможные проблемы
Названия классов и их ID
Методология следования названию классов помогает в 90% случаев. Некоторые сайты автоматически генерируют названия класса (привет, WineStyle!) именно для того, чтобы их не парсили. В этом случае иногда помогает привязываться к id блока, а не его class. А иногда – ен помогает.
Использованиt заголовков и user-agent
Некоторые серверы не пускают вас к себе, если у вас пустой заголовок запроса. Вэтом случае. А некоторые сайты просто показываются разный контент для разных user-agent-ов (хотя это люто наказывается поисковиками). Да и вообще – генерируя десятки (а то и сотни) запросов в секунду нужно быть готовым к бану. Для работы с этим лучше использовать библиотеку user-agent:
from user_agent import generate_user_agent
headers = {'User-Agent': generate_user_agent(device_type="desktop", os=('mac', 'linux'))}
page_response = requests.get(page_link, headers=headers)
Таймаут
Библиотека requests будет ждать ответа от сервера бесконечно долго, поэтому, лучше ограничить ее в этом удовольствии, установив тайм-аут.
page_response = requests.get(page_link, timeout=5, headers=headers)
Коды ответа сервера
Рано или поздно вас забанят. Чтобы нормально обрабатывать это событие, нужно смотреть коды состояния ответа сервера. При бане часто отдаются коды 404, 408, 403, 500.
try:
page_response = requests.get(page_link, timeout=5)
if page_response.status_code == 200:
# начинаем парсинг
else:
print(page_response.status_code)
# уведомляем и пробуем еще
except requests.Timeout as e:
print("Время передохнуть")
print(str(e))
except # остальные исключения
Можно использовать и другую конструкцию для обработки HTTP-исключений:
from urllib.request import urlopen from urllib.error import HTTPError from bs4 import BeautifulSoup try: html = urlopen("https://www.python.org/") except HTTPError as e: print(e) else: res = BeautifulSoup(html.read(),"html5lib") print(res.title)
Вторая конструкция позволяет более детально проанализировать все ошибки и разобраться в их причине.
Смена IP адресов
Библиотека Requests приятна еще и тем, что по умолчанию поддерживает работу с прокси. Делается эо следующим образом:
proxies = {'http' : 'http://10.10.0.0:0000',
'https': 'http://120.10.0.0:0000'}
page_response = requests.get(page_link, proxies=proxies, timeout=5)
Мины
В английском языке это явление называется Honeypots («горшочек c медом»), хотя термин «мина» мне нравится больше. Мина – это небольшая ссылка, не видимая для пользователя (например, ссылка-пиксель белого цвета), переход по которой детектируется сервером, после чего сервер банит IP, с которого пришел запрос.
Я защищаюсь от такого рода «мин» способом, достаточно простым: я заранее загружаю список URL, и заставляю скрипт идти по конкретному и конечному списку адресов, никуда не переходя.


